DHIS2 and longitudinal health records: Connecting systems to get the best of both worlds!
DHIS2 is a health information system that revolutionized the way healthcare data is managed. It is open source and is a byproduct of a multinational action research project initiated from Oslo and first implemented in India. 1Currently, DHIS2 is the world’s largest health management information system (HMIS) platform, in use by 67 low and middle-income countries. 2.28 billion (30% of the world’s population) people live in countries where DHIS2 is used.

DHIS2 is a public health information system (PHIS) where the unit of management is a group or a geographical region and not individuals. It is unfortunate that this distinction between a typical EMR (a longitudinal health record) and a public health information system to manage population health is not clear to many policymakers.
The growing popularity of machine learning and artificial intelligence applications make the PH agencies rethink their data management strategies. A longitudinal health record is essential for most ML and AI applications for creating complex predictive models. PH agencies are gradually realizing the importance of data warehouses in managing the changing healthcare data management applications and workflows. Hence, the next generation of public health information systems should be able to efficiently handle longitudinal as well as group/cross-sectional data.
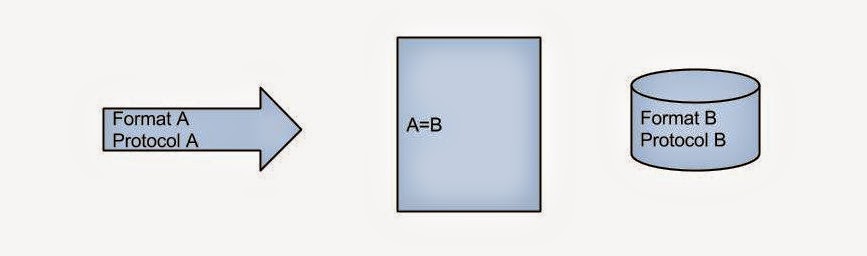
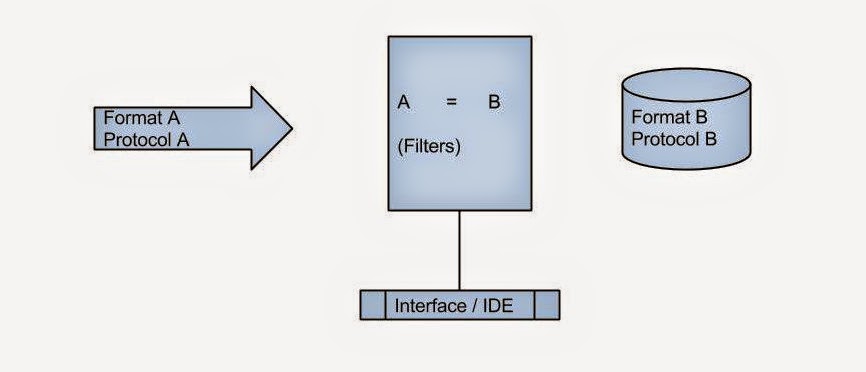
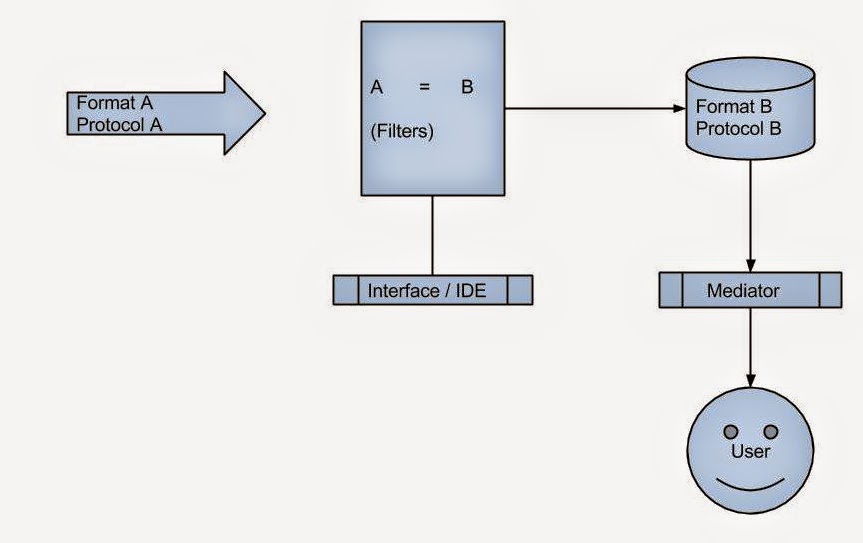
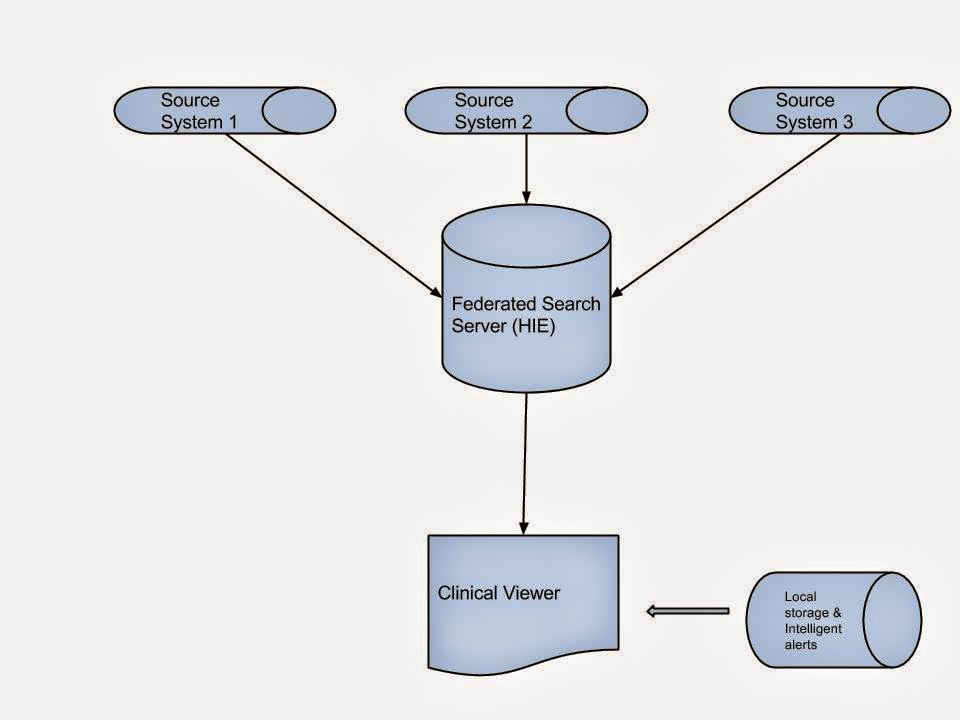
The easiest strategy to adopt may be to make existing PHIS systems talk to each other by leveraging the recent advances in health information exchange. HL7 may not be ideal for this purpose as it relies on a patient-centric model. FHIR may be more capable to deal with this, but the underlying REST interface may not support real-time data exchange.
RabbitMQ and Apache Kafka are industry standard open-source messaging frameworks that can be leveraged for real-time communication between disparate systems such as DHIS2 and OSCAR EMR / OpenMRS. DHIS2 supports both out of the box, and I have modified the DHIS2 docker container optimized for message exchange. A sample Java client is also available from my fork. The repo is here.
If you have ideas/want to work on creating DHIS2 connectors for EMRs like OSCAR EMR or OpenMRS, please comment below. OpenMRS has an existing module that can pull certain reports from DHIS2.
References